Fabric LLM
Our edge-first high-performance AI framework transforms any consumer device into a capable inference and fine-tuning node. No central clouds, no massive data centers, no vendor dependency.
From Android and Apple smartphones to high-end workstations and even industry-grade mainframes, our unified system allows LoRA fine-tuning directly in the llama.cpp ecosystem so you can initialize, train, checkpoint and merge adapters locally for maximum privacy and resilience.

// For Apple Silicon curl -L https://github.com/tetherto/qvac-fabric/releases/download/ v1.0/qvac-macos-apple-silicon-v1.0.zip -o qvac-macos.zip unzip qvac-macos.zip cd qvac-macos-apple-silicon-v1.0# Download model mkdir -p models wget https://huggingface.co/Qwen/Qwen3-1.7B-GGUF/resolve/main/ qwen3-1_7b-q8_0.gguf -O models/qwen3-1.7b-q8_0.gguf# Download dataset wget https://raw.githubusercontent.com/tetherto/qvac-fabric/main/ datasets/train.jsonl# Quick test with email style transfer ./bin/llama-finetune-lora -m models/qwen3-1.7b-q8_0.gguf -f train.jsonl -c 512 -b 128 -ub 128 -ngl 999 --lora-rank 16 --lora- alpha 32 --num-epochs 3
Cross-platform scalability
Our solution provides universal compatibility across the entire desktop GPU ecosystem, including AMD, Intel, NVIDIA, and Apple architectures. By leveraging Vulkan, we ensure your sensitive datasets never leave your control while maintaining total operational resilience.
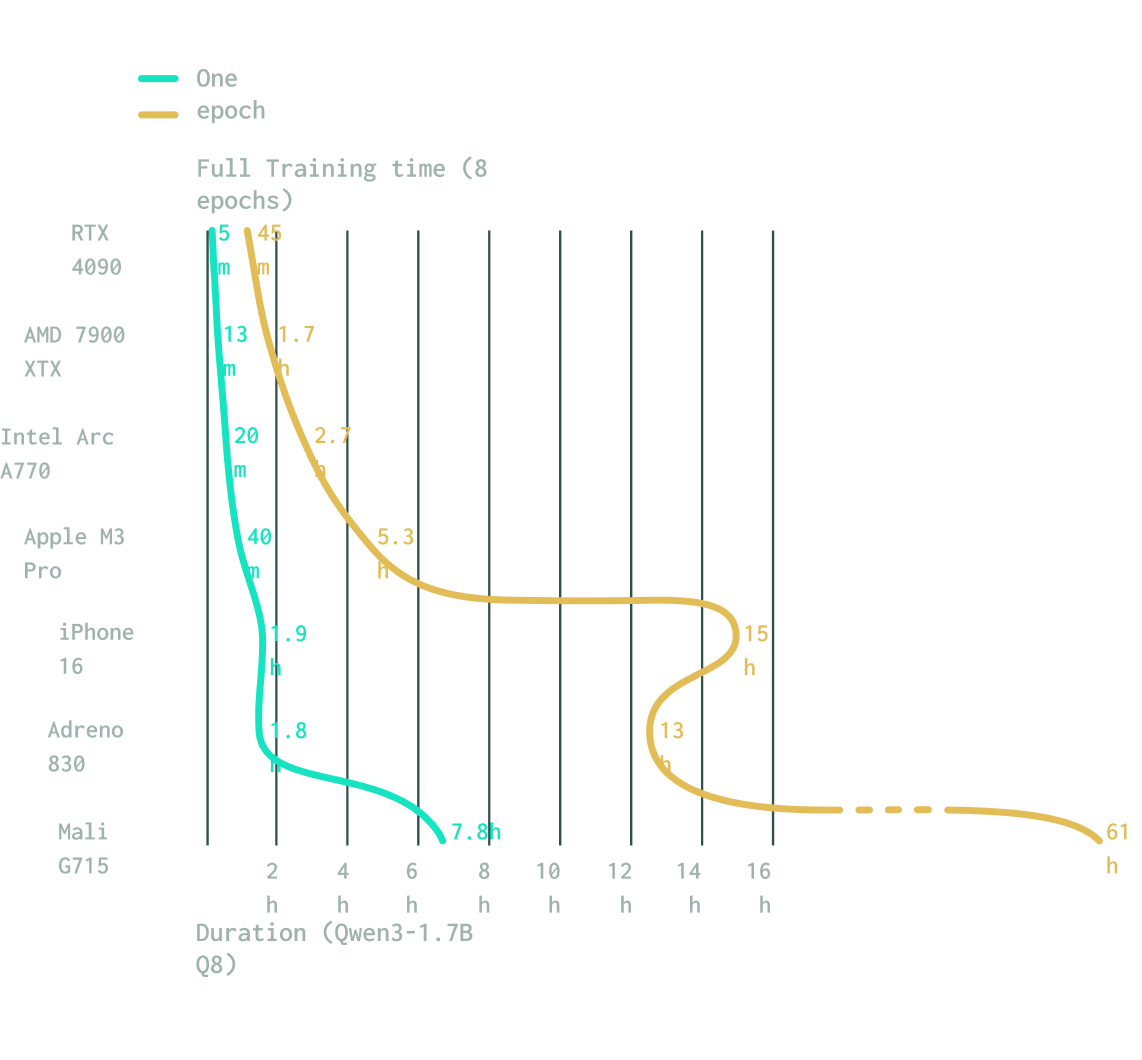
Train anywhere
Whether it's Adreno, Mali, or Apple, our novel dynamic tiling algorithm lets you train wherever you are. Fabric is the first to offer this previously unsupported capability.

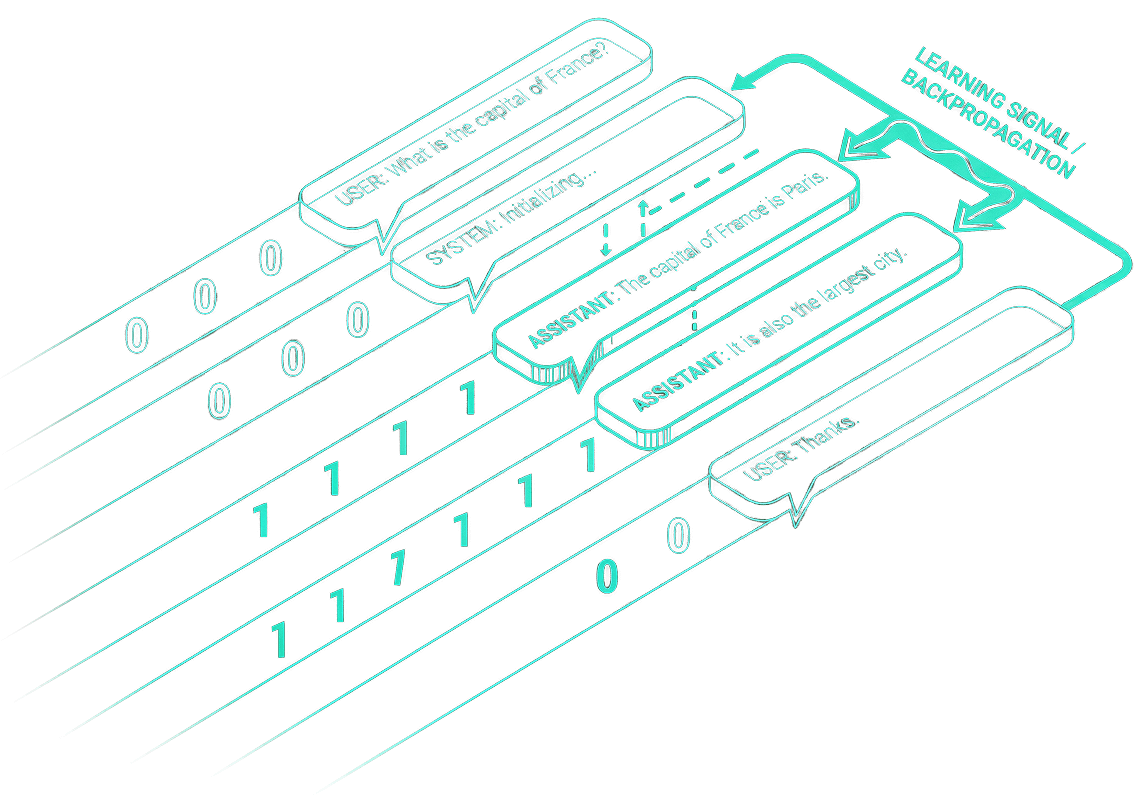
Only assistant responses
We implemented masked-loss training, where a mask is applied to train only on assistant tokens. This ensures that user and system messages influence the context but not the loss and that the same tokenization and masking logic are used consistently during both dataset creation and loss computation.
FAQ
Unlike legacy frameworks that require CUDA, our solution supports virtually all modern consumer hardware. By leveraging Vulkan and Metal backends, you can train on Android (Qualcomm Adreno, ARM Mali), iOS and macOS (Apple Silicon), and standard Windows/Linux setups (AMD, Intel, NVIDIA).
Mobile GPUs often have strict memory limits (such as the 128MiB SSBO limit on Adreno) that cause standard training attempts to fail. We engineered a novel dynamic tiling algorithm that breaks large matrix operations into smaller, manageable tiles, enabling stable training of large models like Qwen3 on mobile devices.
While standard llama.cpp is excellent for inference, its training capabilities were historically limited to the CPU and lacked instruction-tuning logic. We integrated a full LoRA workflow with GPU acceleration and introduced masked-loss training, allowing you to train models to follow instructions rather than just completing text.
Instruction fine-tuning allows models to learn directly from target responses, a critical capability for aligning models to follow instructions.
Masked-loss training is the core mechanism that makes instruction fine-tuning work. Masked-loss ensures the model learns only from the assistant responses while ignoring user and system prompts during the backward pass. This is critical for instruction tuning, as it forces the model to align its behavior with the desired output rather than simply mimicking the input structure.
No. All fine-tuning happens locally on your hardware. This eliminates the need for cloud data egress or API keys, making it ideal for high-stakes domains like healthcare or enterprise applications where sensitive datasets must remain private and under your full control.
Our benchmarks indicate near-parity with established frameworks. In biomedical Q&A tasks, our QVAC Fabric LLM models achieved accuracy (79–94%) and win rates comparable to models trained on PyTorch, demonstrating that you can achieve professional-grade results without a data center.
Or copy link into your Keet app
keet://chat/nfo61f4e6zc5t1ifncyh9yp7s5eynbruz5bs95oc5ufn3e79entmhix74miigc8iz9iawfrb7pzk3am8eotxw8wat7554etbn7d6j4ho84b1zqnb63z7hxq1ubt5w4wi4kpq3mdgpijcnaifnhm7sy4cfxqqoyedpnb5qg1majcggy4s9s91fgtg3khgw