Genesis: Largest synthetic datasets for LLM training in STEM domains
Genesis provides the global AI community with the high-quality data needed to level the playing field, accelerating the development of open-source LLMs that compete with leading closed-source / proprietary models.
Genesis II
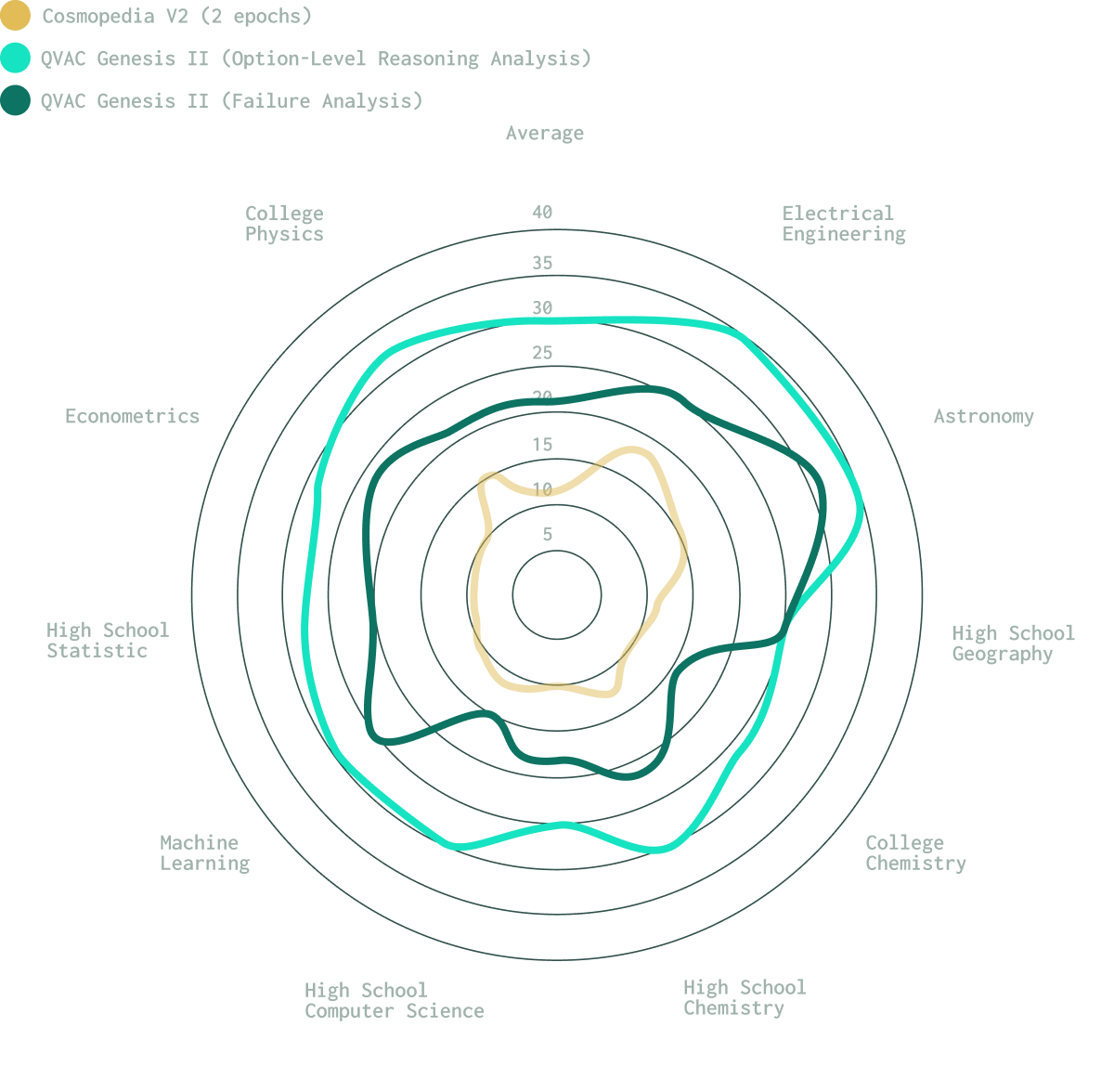
The second release of QVAC Genesis expands coverage to 10 new domains, for example chemistry, computer science, statistics, machine learning, astronomy, and econometrics, while also introducing an improved methodology that produces higher-quality synthetic datasets.
More than a scale increase, our research aims to empower the community to develop models that reason and explain, grounding intelligence in understanding not imitation. A deliberate shift in how educational AI data should be built.
Genesis I
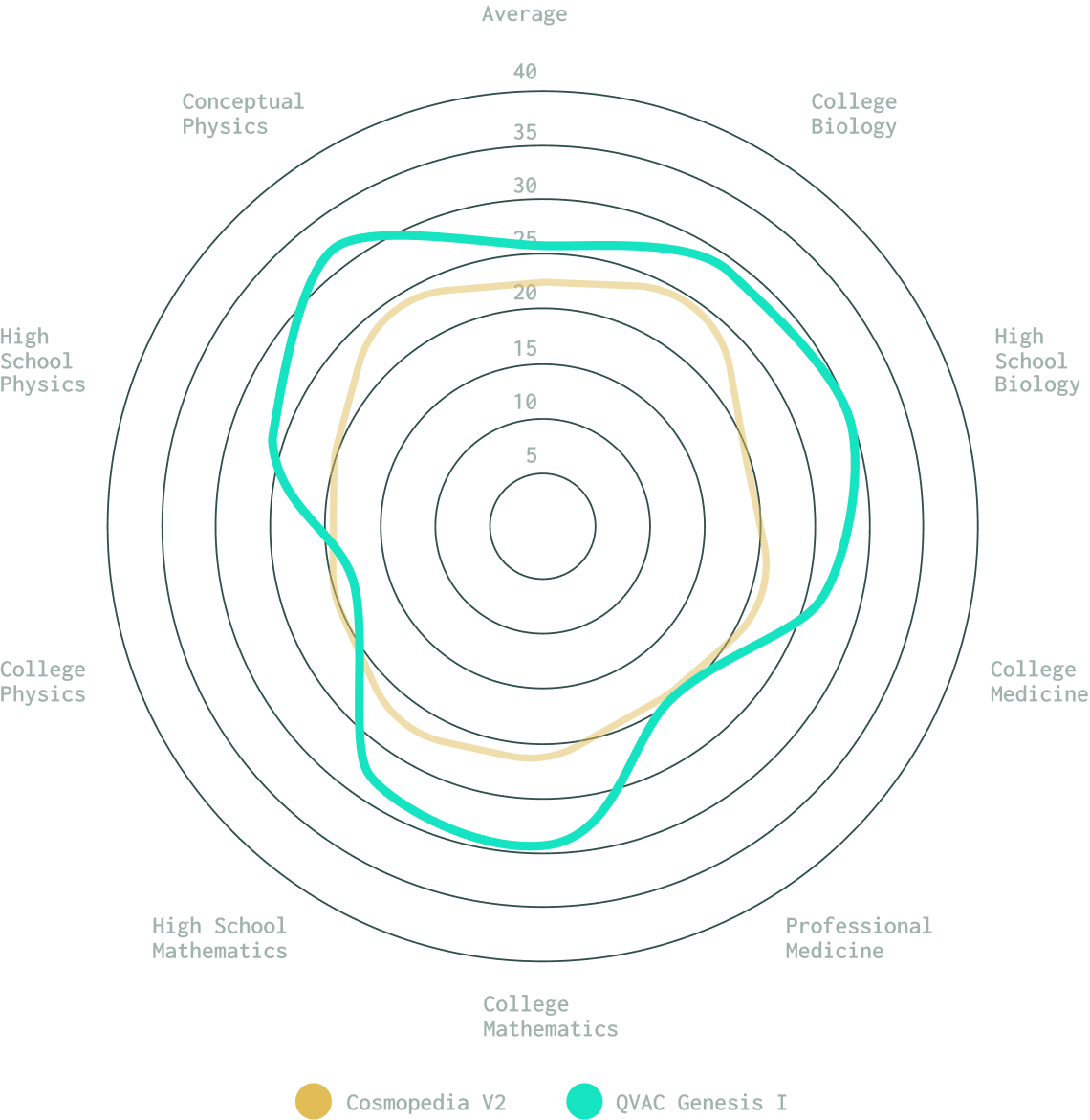
We start with Genesis I, a synthetic dataset purpose-built for education-specific content, offering deep and comprehensive coverage across key STEM domains.
The high-quality dataset has been rigorously validated across multiple educational benchmarks, demonstrating superior performance across school and college-level subjects like Logical Deduction, Mathematics, Biology, and Medicine.
FAQ
QVAC Genesis is a family of synthetic datasets developed with the focused goal of improving language models in areas where they struggle to reason, generalize, or solve problems. It captures systematically identified weaknesses and transforms them into high-quality, domain-specific learning instances.
With the release of QVAC Genesis II, the QVAC Genesis family now totals 148 billion tokens across 19 educational domains. It distinguishes itself by moving beyond simple "imitation" of fluency to ground intelligence in understanding. This is achieved through a deliberate shift in how data is built, helping models explain why something is true rather than just predicting what sounds right.
While naturally occurring datasets provide broad coverage of general knowledge, they often lack the specific reasoning patterns or domain-level nuances required for a model’s target capabilities. In contrast, synthetic data enables the deliberate creation of examples that align precisely with the behaviors or reasoning skills you want the model to learn. By designing and scaling such data, we can ensure a balanced and controllable mix across domains, languages, and task types, something that naturally occurring data rarely achieves.
The combined QVAC Genesis ecosystem now totals 148 Billion tokens. This includes the original 41 Billion tokens from QVAC Genesis I and an additional 107 Billion new tokens introduced with QVAC Genesis II.
A system with an 8-core CPU, 32 GB of RAM, and 200 GB storage. Python 3.9 or newer and dependencies like huggingface_hub and datasets.
Yes. Just use our base evaluation model Genesis I and compare your results. You can find it at https://huggingface.co/qvac/genesisI-model.
QVAC Genesis I was pre-trained using standard PyTorch Lightning, whereas QVAC Genesis II models are pre-trained using Megatron-LM and Megatron Core, NVIDIA’s open-source framework purpose-built for training extremely large transformer-based language models at scale. Megatron provides highly optimized CUDA kernels, mature tensor parallelism, and communication patterns refined through years of large-scale training. While PyTorch remains widely adopted across the AI community, QVAC Genesis II leverages Megatron Core to achieve significantly higher efficiency and scalability, rather than relying on general-purpose PyTorch training pipelines.
QVAC Genesis I covered four key domains: Physics, Biology, Mathematics, and Medicine.
QVAC Genesis II significantly expands this coverage to 19 total domains. New additions include Chemistry, Computer Science, Statistics, Machine Learning, Astronomy, Geography, Econometrics, and Electrical Engineering. Additionally, the College-level Physics domain has been regenerated using higher-quality seed data and improved methodologies.
High school and college level.
English-only.
We evaluate using MMLU subsets aligned to our subject areas and report per-domain and overall (macro-average) accuracy.
Independent evaluations of QVAC Genesis II show that models trained on this data demonstrate substantially higher reasoning accuracy and produce clear, unambiguous answers more consistently than models trained on prior synthetic datasets.
We use a multi-stage pipeline where reasoning models evaluate and correct answers to ensure factual accuracy. The new Option-Level Reasoning methodology further enhances this by analyzing all answer options to ensure clarity and causality.
During curation we used a high-quality classifier to filter seed data, then a reasoning "judge" to score and keep only the best items and those where state-of-the-art small models made mistakes.
We use a sophisticated pipeline tailored to education that includes curating high-quality seed data and generating level-aligned Q/A targets. With QVAC Genesis II, we have implemented a dual-method pipeline:
Failure Analysis: We use reasoning "judges" to score items and retain cases where state-of-the-art small models make mistakes.
Option-Level Reasoning: This new approach analyzes every answer option in a multiple-choice question (not just the correct one) to reinforce correct reasoning while explicitly addressing common misconceptions.
The seeds come from FineFineWeb which has been rigorously classified for education content. However, there is no guarantee the datasets are free from biases and inaccuracies because the origin is from web data. Also, since the data were generated using LLMs, there are possibilities of biases and inaccuracies.
We use a four-stage pipeline tailored to education: (1) curate high-quality, domain-specific seeds, (2) generate level-aligned Q/A targets via prompts, (3) produce answers with small-model and score them with strong reasoning-model “judges” to surface hard cases, and (4) run a final reasoning-based review to correct failures, standardize style, and ensure safety.
The QVAC Genesis datasets are uploaded to HuggingFace and can be downloaded from there or using the specific APIs.
The QVAC Genesis datasets are made available under a Creative Commons Attribution Non-commercial (CC-BY-NC 4.0) license. This supports researchers, academic institutions, and independent developers and reinforces our commitment to open, community-driven AI research.
The QVAC Genesis data is completely synthetic and generated from open-source datasets as seed. To safeguard quality, we perform extensive checks for duplicates in web data (to detect potential copyright content), as well as for personally identifiable information (PII). We will take appropriate actions in response to notice of copyright infringement. If you believe your work has been used or copied in a manner that infringes upon your intellectual property rights, please email data-apps@tether.io identifying and describing both the copyrighted work and alleged infringing content to file a notice of infringement.
Genesis is optimized for training small-to-medium base models and for pre-training stages where education-focused knowledge and structured Q/A are beneficial.
Yes. The dataset is provided in multiple formats (Q/A, dialogue, article/textbook-style passages) and organized by subject and difficulty so researchers can select subsets appropriate for fine-tuning.
Genesis adds education-focused, synthetic pre-training material designed to fill topical gaps in existing corpora (e.g., subject-aligned Q/A and structured learning examples) and to provide targeted examples that improve downstream performance in educational tasks.
We welcome contributions and feedback via the Hugging Face dataset card. Feel free to initiate new discussion and/or open new pull requests.
Documentation, dataset cards, and usage examples are all published on our HuggingFace space and in accompanying blog posts on the HuggingFace blog.
We focused on producing high-quality, domain-aligned educational data to lower entry barriers for open-source LLM development. Our process emphasizes transparent methodology, multi-stage validation so researchers can build and evaluate models responsibly.
Web seeds are sourced from FineFineWeb and undergo classifier-based filtering to retain only relevant educational content within specific domains. We also conduct toxicity tests to identify and remove potentially harmful material. However, no automated process can guarantee complete elimination of harmful content, so an additional safety check is required before using the data in production.