

QVAC MedPsy is a free, open-source medical AI model that can run entirely on your own device, with no cloud and no data leaving your phone. It ships in two sizes, 1.7B and 4B. On standard medical benchmarks, the 4B version matches or beats Google’s MedGemma-27B, a model nearly seven times larger, while the 1.7B version is small enough to run on an ordinary smartphone.
The headline is simple: better training beat raw size. MedPsy reaches the level of models two to seven times bigger, not by being huge, but by being trained more carefully on higher-quality medical data. And because you can run locally, the most sensitive data there is, your health, never has to travel to someone else’s server.
A private medical AI model built to run on your device
MedPsy is a family of small medical language models developed by Tether Data’s AI Research group as part of the QVAC platform, Tether’s open-source, local-AI ecosystem. It answers everyday medical questions and walks through clinical reasoning in clear, plain text. There are two sizes: MedPsy-1.7B for phones, and MedPsy-4B for high-end phones and laptops. Both are built on open Qwen3 models and released under the Apache 2.0 license for research and educational use. Both models are available on Hugging Face, in their full version and as smaller compressed versions that run efficiently with llama.cpp or the QVAC SDK.The QVAC SDK provides out-of-the-box optimal execution support, offering a simple library that runs locally on any device, from a phone to a laptop or server with seamless cross-platform behavior, delegated inference and peer-to-peer (P2P) capabilities.
Disclaimer: MedPsy is a general medical model for question-answering and clinical reasoning. It is not a mental health, therapy, or crisis-support tool, and has not been trained or validated for that.
Better training, not raw size
In AI, how you train a model matters as much as how big it is. The QVAC team focused on the quality of the medical training data and a careful, multi-stage training process aimed squarely at medicine, instead of simply scaling up parameters. A model that specializes deeply in one field can outperform a much larger model that tries to know everything.
The training data was built using QVAC Genesis II synthetic medical datasets, which cover diverse medical domains such biology, chemistry along with publicly available open-source medical QA prompts. The datasets were used as seeds by a strong teacher model (Baichuan-M3-235B) to generate chain-of-thought traces, extended rationales, and decision-oriented answers to improve the model’s quality. For more information about the training methodology, see here.
There is a practical bonus. MedPsy-4B reaches its answers using about 3.2 times fewer tokens than the general model it is based on. Fewer tokens means faster replies and less battery used, which is exactly what you want on a phone.
How MedPsy compares to Google’s MedGemma
On the average across closed-ended medical benchmarks, MedPsy-4B scores 70.54 and edges out MedGemma-27B at 69.95, despite being nearly seven times smaller. It leads most clearly on the hardest, most realistic tests: HealthBench, HealthBench Hard and the expert-level MedXpertQA. On a few academic multiple-choice tests it runs a point or two behind. Here is the honest side-by-side.
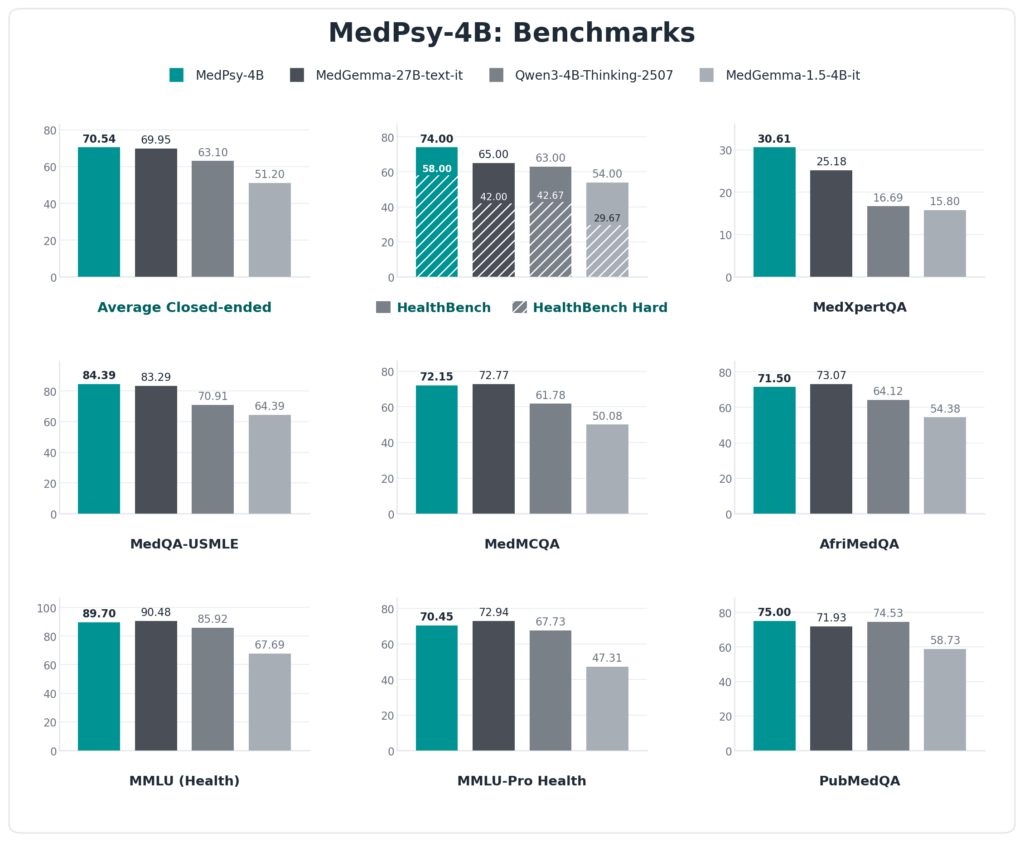
| Medical benchmark | MedPsy-4B | MedGemma-27B |
|---|---|---|
| Average (closed-ended) | 70.54 | 69.95 |
| HealthBench (realistic care) | 74.00 | 65.00 |
| HealthBench Hard | 58.00 | 42.00 |
| MedXpertQA (expert level) | 30.61 | 25.18 |
| MedQA-USMLE | 84.39 | 83.29 |
| PubMedQA | 75.00 | 71.93 |
| MedMCQA | 72.15 | 72.77 |
| AfriMedQA | 71.50 | 73.07 |
| MMLU Health | 89.70 | 90.48 |
| MMLU-Pro Health | 70.45 | 72.94 |
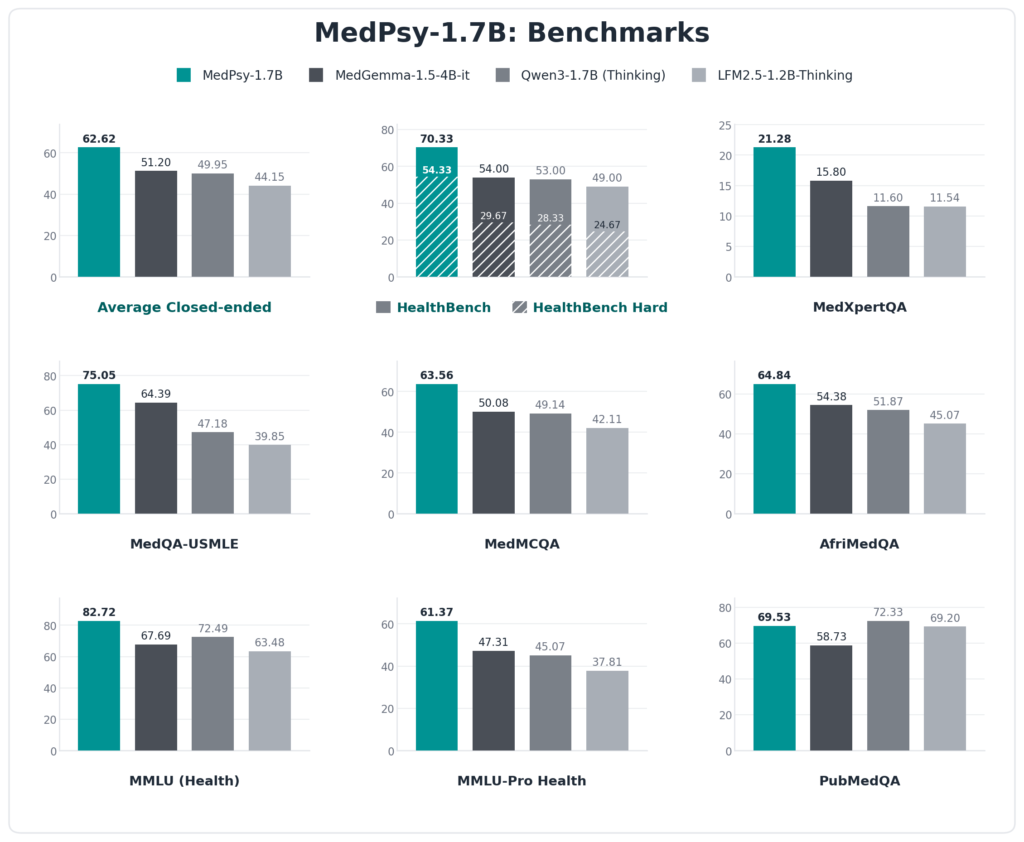
The smaller model tells the same story. MedPsy-1.7B scores 62.62 on average and beats Google’s MedGemma-1.5-4B (51.20) by more than 11 points, while being less than half its size and small enough to run on a normal smartphone.
Why running on your device matters
Health data is the most sensitive data most of us will ever generate. The usual way medical AI works is to send your question to a company’s servers in the cloud. MedPsy flips that: it runs 100% on your device, so your symptoms, questions and notes stay with you. There is no account, no subscription, and nothing to leak.
Running locally also makes it work where the cloud cannot. It keeps working with no internet, on a plane, in a remote clinic, or anywhere bandwidth is scarce. And because it fits on a phone people already own, it does not need an expensive server or a data center to be useful, which matters most in the places that have the least access to care.
How to try MedPsy
The simplest path is the QVAC SDK. Install it, pull a MedPsy model from Hugging Face, and run it on your device:
npm install @qvac/sdkNo API key, no cloud bill. Get the models for free & get started.
MedPsy on Hugging Face
All MedPsy models, GGUF files, quantized variants, and resources in one place.
Open the CollectionMedPsy-4B
Higher-quality edge model. Surpasses MedGemma-27B-text-it on closed-ended medical benchmarks at ~7x smaller.
Open the model cardMedPsy-1.7B
Smartphone-class medical model. Beats MedGemma-1.5-4B-it by +11.42 points on closed-ended; matches Qwen3-4B-Thinking-2507.
Open the model cardMedPsy-4B-GGUF
GGUF repo with an unquantized BF16 export and seven quantized files. Q5_K_M (3.16 GB) adds a high-quality 5-bit tier; Q4_K_M (2.72 GB) remains the recommended size/quality trade-off.
Open the GGUF repoMedPsy-1.7B-GGUF
Smartphone-ready GGUF repo with an unquantized BF16 export and seven quantized files. Q5_K_M (1.47 GB) is nearly lossless; Q4_K_M (1.28 GB) is the best mobile trade-off.
Open the GGUF repoImportant: MedPsy is not a substitute for professional medical judgment, diagnosis, or treatment, and must never be used in emergencies or as a sole decision-making tool. Like any language model, it can produce wrong or incomplete answers. It is text-only, English-only, and released for research and educational purposes. Always consult a qualified healthcare professional.
Frequently asked questions
Is QVAC MedPsy free?
Yes. MedPsy is open source under the Apache 2.0 license and free to download from Hugging Face, released for research and educational purposes.
Does my data leave my device when I use MedPsy?
No. MedPsy is designed to run entirely on your own device through standard llama.cpp inference engine and the QVAC SDK. For the best experience, the QVAC SDK is the preferred platform, offering optimal, out-of-the-box execution designed to provide seamless and highly efficient local inference with additional capabilities such as delegated inference and peer-to-peer (P2P) support. There is no cloud call, so your prompts and any health information you type never leave the device.
Is MedPsy a mental health or therapy AI?
No. MedPsy is built for general medical question-answering and clinical reasoning. It is not trained or validated for mental health, therapy, or crisis support.
Can MedPsy replace a doctor?
No. MedPsy is not a substitute for professional medical judgment, diagnosis, or treatment, and it should never be used for emergencies. Its answers can contain mistakes and should always be checked with a qualified clinician.
How does MedPsy compare to Google MedGemma?
On the closed-ended medical benchmark average, MedPsy-4B scores 70.54 versus 69.95 for MedGemma-27B, despite being nearly seven times smaller. It leads clearly on the hardest realistic health tests, such as HealthBench (74 vs 65) and HealthBench Hard (58 vs 42).
What is the difference between MedPsy-1.7B and MedPsy-4B?
MedPsy-1.7B is small enough to run on an ordinary smartphone and beats Google’s MedGemma-1.5-4B by over 11 points. MedPsy-4B is more capable, targets high-end phones and laptops, and matches models nearly seven times its size.

